At Sykes we have a large number of software developers distributed across multiple teams and timezones. We also adopt continuous delivery meaning that at any moment in time there's likely some code being released or tested.
While iterative development is important to us, so is software quality and reliability. Pull request reviews are a key part of our process.
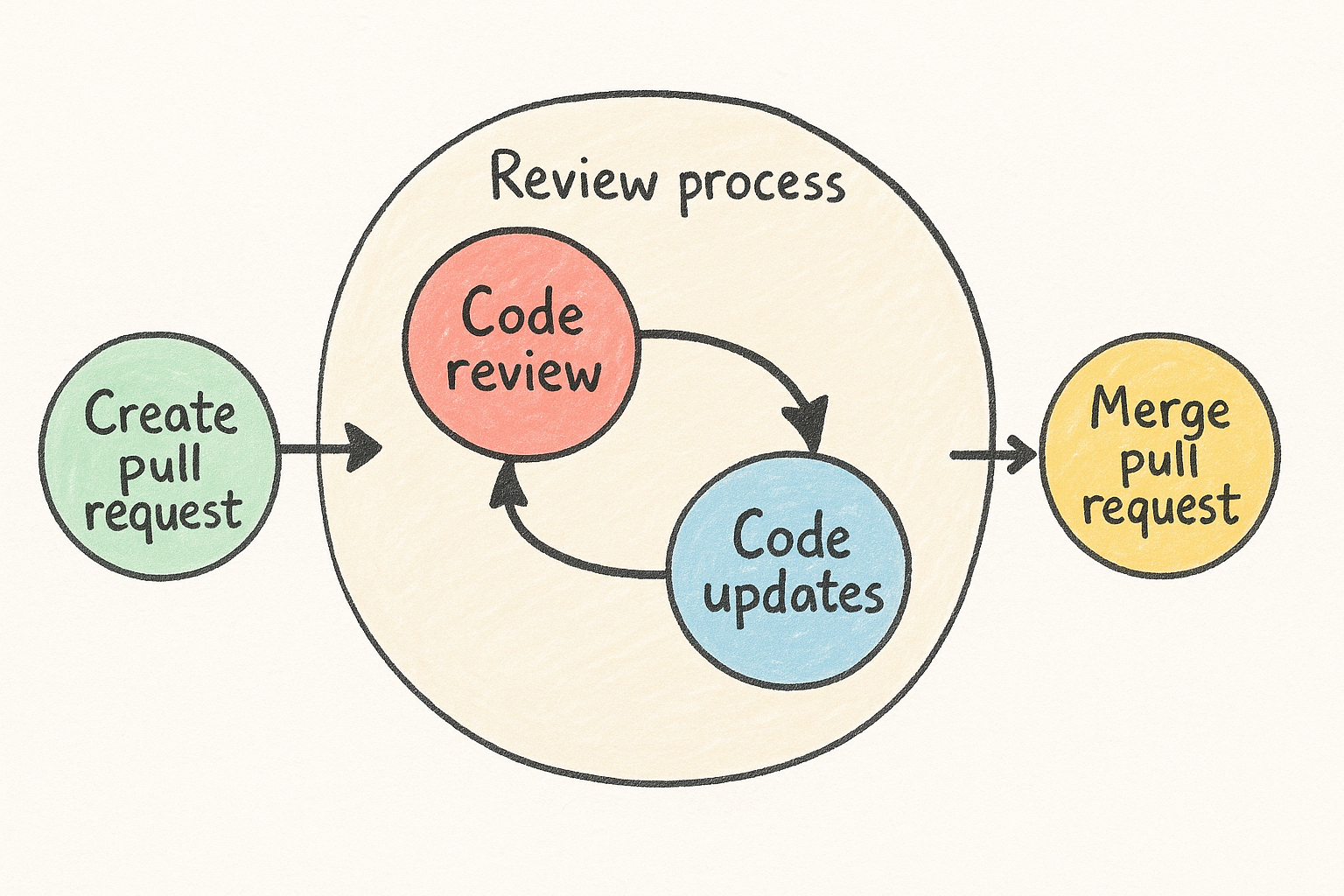
What is a pull request?
A pull request is a request to merge code from one branch into another. This is usually done when a developer has completed a feature or bug fix and wants to add their code into the main branch to release to production.
There can be frustrations in this process - it's essentially a communication exercise between a developer who has written some code and needs to convey what they've done, why, and what makes them confident it's the correct and safe change to make.
In turn, the reviewer needs to communicate unknowns, share their experience, ask relevant questions, and provide a guardrail against mistakes that happen to us all.
It's frustrating - you're trying to release a feature the business needs yesterday, fix a bug you let slip into the wild, or try to get your work merged before you go on holiday.
- Maybe no-one's picking up your PR.
- Maybe someone asked for changes but has been in meetings for 3 days straight since.
- Maybe the developer you asked to make changes is arguing that it's not worth it.
It's easy to see PRs as a bottleneck, a blocker, or a pain in the backside. I hope to convey my view that PRs are an amazing opportunity to share knowledge, learn from each other, and improve the quality of our craft.
Who participates in PR review?

Honestly, the whole team. That's a bit of a cop out, but it's true.
The basics:
- The developer who wrote the code
- A developer who can approve the code to be merged
At Sykes we have a varying level of review required for different codebases. Some of the critical codebases (for example around authentication, payments, or data protection) require review by an architect.
Others may require a lead developer. Others require any of a pool of developers that are senior enough (or experienced enough in the codebase) to evaluate risk and impact.
You mentioned a cop out?
However - I strongly feel that everyone should participate in review. I often speak to junior developers or graduates who join us and say
"I don't feel like I can review this code, I'm not experienced enough"
"Am I allowed to review this code? I don't want to step on anyone's toes"
"I don't want to be the one to approve this code, and then it breaks everything"
I always tell them not to worry. You're undervaluing yourself if you think a fresh pair of eyes adds nothing. You could spot something that the developer missed, or you could ask a question that no-one else thought to ask.
Worst case, you learn something new. Best case, you spot a bug or a security issue.
"I prefer reviews from junior developers - if my code isn't clear to them, it's not clear code."
-- Scott (Solutions Architect)
If as a junior developer your approval allows something to go to production that shouldn't - it's not your fault. Approve the PR if you're happy with it, but a correctly set up system would require multiple approvals anyway.
Reading the PRs of developers working in a similar area to you is a great way to learn. You can see how they approach problems, how they structure their code, and how they document their work.
Writing a bad PR
This is by no means an exhaustive list, but they're some common things I try to avoid.
Not documenting the aims of the code in the description or linked ticket
Often, the reviewer will have no context of the code. They may not be in your team and may not even know your work is going on at all. Opening your PR may be the first time they see all of that.
Remember, you've been working on this for a while. You know the code inside out. You know what you're trying to achieve, and you know how it works. The reviewer doesn't.
Tiny code change with no context
Context is the be-all and end-all of confidence in software code changes. I need to be able to see enough of the direction you're going and what you might impact in that PR.
If code is split up too much the overall context is lost.
You'll also find that tiny PRs get the most scrutiny. If you have a small change, it's likely that the reviewer will look at it in more detail than a larger change.
Huge code change spanning the entire codebase
Intuitively, huge code changes are tough to review. Often they aren't really reviewed at all - just blindly accepted if tested and working. This is a huge risk to take, and often leads to bugs in production.
No automated tests or manual test evidence
A picture speaks a thousand words. A video speaks a million. If you can show the reviewer what you've done, and how it works, then it's much easier for them to understand what you've done.
This is especially true if there are UI changes. If you're building an interface the way things look are part of the review as well - not just the code you've used.
If there is no evidence of manual testing, and there's no automated tests, then the reviewer has no way of knowing if the code works. You're essentially asking them to check it out and test it themselves.
Writing a good PR
Doing the inverse of the above is a good start.
- ✏️ Spend time writing up the PR description. Even if you're duplicating some stuff you wrote on a ticket or a Teams message, provide context and test evidence.
- ⚖️ Aim for a PR that is small enough to be reviewed in a reasonable time, but large enough to provide context.
- 🧠 Write a PR which delivers a slice of functionality in which the code changes have a high locality. The reviewer needs to be able to understand what you're doing without having to run your code
- 🧪 Test your code and provide evidence you've done it.
- 💬 If you think it'll help, add comments to the PR yourself to provide additional context or preempt common questions.
- ⏰ If a PR is urgent, then make sure you communicate that. If you need it reviewed in the next 30 minutes, then say so. If you need it reviewed by the end of the day, then say so. If you need it reviewed by the end of the week, then say so.
Performing a bad PR review
Some of the behaviours I have noticed in myself and others in objectively poor PR reviews include:
Not looking at the ticket / description
If someone has put effort into writing up a PR or linking it to a well written ticket and you don't read it, you're missing out on a lot of context.
I've certainly been guilty of leaving comments, then getting to the bottom of the PR and deciding to read the description - just to realise my comments were completely invalid.
Stopping as soon as I've found a problem
I do this one too much too - it's easy to find a few issues and leave some comments on them and then kinda just - stop. It's frustrating for the developer because if I'd carried on and found that other issue they could have fixed it at the same time.
Frustrating for me because I could have saved myself time by not having to review it again and again.
Not explaining the why
PRs are as much a learning opportunity as they are a protocol or safeguard. If you don't explain why you think something should change, or how you would make the change the developer is often no better off than if you hadn't commented at all.
Change this to use the write connection.
versus
You've just written to the database, you should read from the write connection to ensure you're getting the most up to date data during periods of replication lag.
Not clearly stating my expectations
There are different types of comment and action on a PR. You can request changes. You can approve. You can leave a comment and do neither. How does the developer know what you expect from them?
Forgetting the person
Change this.
Don't do that.
???.
I've rewritten this.
wtf
Human linting
I think this line isn't indented correctly. This variable is camel case instead of snake case.
Not stepping up the conversation
Sorry, I don't have time for a call. I've left a comment on the PR. Just fix it and I'll approve it.
Performing a good PR review
A good PR review is one that is thorough and provides constructive feedback. It should also be done in a timely manner to ensure that the code can be merged and released as soon as possible.
- 💚️ Be kind. It's difficult to convey tone in a comment. It's easy to come across as rude or dismissive. If you think something is bad, say so - but explain why. If you think something is good, say so - and explain why.
- 💯 Read the whole PR. It's fine to focus on a critical issue but don't drip feed the rest.
- 🔍 Clarify your comments:
- 🔴 If there's a major issue with a PR which means it can absolutely not be merged explain why and request changes on it.
- 🟠 If there's a minor issue you're leaving up to the developer to come back to you on, then leave a comment and leave it unapproved.
- Be prompt on a followup review if they address or otherwise resolve your comment.
- 🟢 If there's an issue which can be fixed in a followup PR or is educational and you hope the developer will take on board, mark the comment as minor or a nit and approve the PR.
- 💬 Put the extra time into explaining your comment and what you're trying to achieve. Why are you concerned by a particular piece of change. What would you do, and why?
- 🌟 If someone has written good code, or covered an edge case you hadn't thought of - leave them a positive comment. +1s can make people's day. It's easy to see PR review as an exercise in problem detection, but it's nice to highlight great work too.
- ✨ Don't lint the code. If it's a code style issue that keeps coming up add a linter or code quality tool that will catch this in the test pipeline.
Receiving feedback

It can be difficult to be vulnerable with your work and send it out for review. It's easy to feel like you're being judged or that your work isn't good enough.
But remember, you're not alone. Everyone has been there. Everyone has had their code reviewed and everyone has had to review someone else's code.
Try to treat a PR review as an opportunity to learn and improve.
Reviewers are almost never judging you and your ability.
We're judging the code and your approach. We have all the time in the world* to help you improve and learn. We want to see you succeed and grow as a developer.
*maybe not all the time in the world, but we'll try our best
Asynchronous collaboration
But I need $otherDeveloper to merge their PR!
If you're working on a frontend feature that will talk to a database or API that is under development, it can be tempting to say "I can't progress this, I need that work merged."
A key approach here is to try to decouple your work from the other developer's work. If you can, try to make your code work with a stub or mock of the API. Perhaps you commit a static JSON file or array that contains data of the correct shape.
You can then completely develop your UI (except for stuff like pagination or interactivity) and get feedback on it without waiting.
There's no reason that stubbed data can't go into production assuming your change is behind a feature toggle or other experiment control that means real users can't see it.
Once the other developer's work is merged, you can then remove the stub and replace it with the real API call. That can be a separate PR which has a reduced scope (you don't need feedback from UX on your design implementation - for example).
Stacking them up
A challenge I sometimes hear is that someone is blocked because of a PR taking a while or getting knocked back.
While this is valid and can need escalating or sorting out I think it's important developers have the tools to continue working regardless of external dependencies.
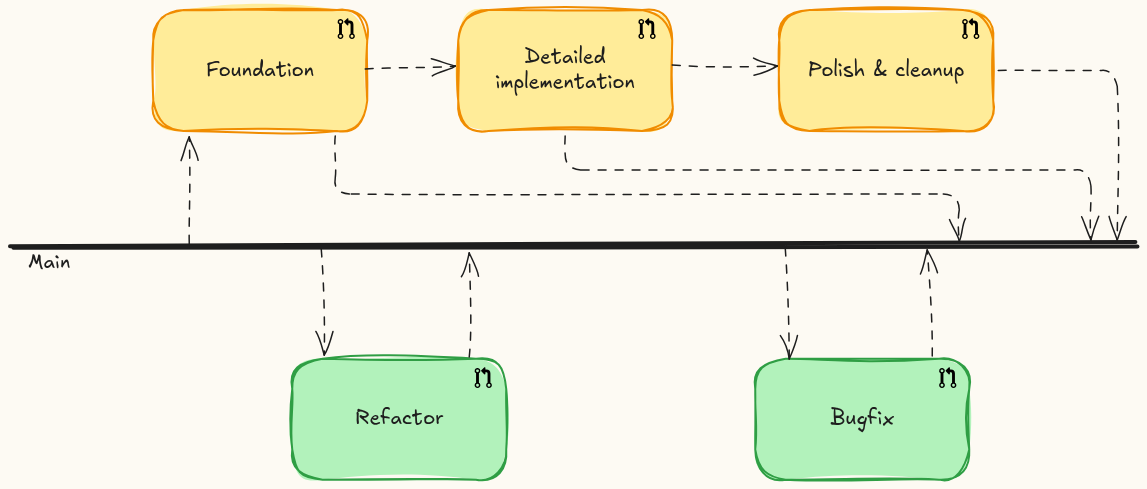
A potential superpower I don't see used as much as I think it should be is stacked PRs. If you've got a slice of work ready, branch off it and continue working.
If you finish that second piece of work, you can make a PR from your new branch to the older one. If the older one needs changes in the meantime, you can rebase the newer one afterward.
Once the old one is merged you can retarget your newer PR to the main branch.
This is especially useful if you have a foundational PR that has no entry points (and so cannot break production) but adds a layer of code that you can build on top of.
Sometimes if you have a few PRs you can ask the same reviewer to go through them, and they can maintain the context of the overall feature combined with nicely sized slices of functionality.
Rabbit holes
At Sykes, we try to apply the campsite rule - leave everything you touch a little bit better than you found it. If everyone does this you can tackle technical debt and make your codebase a nicer place to work.
Unfortunately, this can lead to your PR becoming larger and larger as you clean up a bit of code, refactor something else, or fix a bug you didn't even know existed.
When this happens, it's usually better to split changes that can stand alone into their own PR. It'll be focused and easier to test and can go into production quite quickly.
I like to combine this approach with the above when I'm working on a complex feature. I'll end up with a few incremental PRs which follow each other, and then some incidental bugfixes or refactors that can go in separately.
Though it might seem like more PRs would be slower, in my experience they tend to be merged faster and with less risk. The downside can be conflict resolution and having too many different things in flight. If you're changing an area of the codebase other developers are actively working on, it fits less well.
Closing thoughts
I've learnt so much from both sides of the PR process over the years. I've learnt how to write better code, how to communicate better, and how to work better with others.
Don't take feedback (too) personally - and be kind to each other - if in doubt hop on a call or grab a coffee and talk it through.
About Sykes
The thoughts shared in this article were produced by the development team at Sykes. If you want to work on software challenges at scale, check our current vacancies.