
This article explains how we prepared the website for an unknown amount of traffic.
About Sykes
The techniques shared in this article were produced by the development team at Sykes. If you are a talented Data Scientist, Analyst or Developer please check out our current vacancies.
Context
Handling a variable amount of traffic is a day to day operation at Sykes, we have auto scaling enabled on the Sykes platform, this allows us to handle web traffic in a cost effective way, which also scales up automatically, with the limiting factor being cost of services.
TV traffic is not normal traffic though, especially on a prime time slot on a Saturday night.
For example, think of a supermarket, with 10 checkouts. If there are a small amount of customers, the staff will not be sat at a checkout, but doing other jobs. If a queue starts to build, an alert is sent to the other members of staff, who stop what they are doing and open a checkout, and help serve the customers.
This is similar to how our website auto scales, we use Fargate and try to keep machines at about 50% CPU use, so if the average falls below 50%, we can remove a server, and if above 50% we can add a server, the percent CPU use in this case is the member of staff at the till pressing the button for a new checkout.
This allows us to run the website in a cost effective way, as most traffic is based on curves (see below), we can make a pretty good call on the servers needed.
TV Traffic
TV Traffic is different, it's more similar to the Slashdot effect we had to prepare for an unknown, unnatural traffic pattern, we assumed it would be a sawtooth with a very steep leading edge and a slow gradual trailing edge.
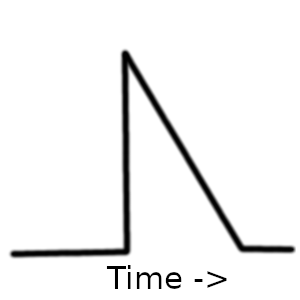
The unknown part is how high the traffic will go. The viewer base on the show at the time was around 8.5 million. So it has the potential to be quite high, even if 0.5% of people (1 in 200) look for Sykes online when the see the section, that is still 400k hits in a very small amount of time, where the auto scale would not be able to react fast enough.
We also did not know what this traffic would do, but assumed it would not be a "standard" user to the website, who is actively looking for a holiday. To go back to the Supermarket example, if a large bus turned up unexpected and all passengers bought a single bottle of water, that customer is nothing like the normal profile of a customer, and checkouts are just one of the issues the supermarket would have.
Not knowing how the traffic would behave, we pre-scaled everything which could effect their journey up, and also turned off background processing tasks, so that we had the most processing power available,the background processing jobs could just catch up later on.
We had also discussed second peaks for things like +1, but assumed they would be much easier to deal with.
There are 3 parts to this formula, the incoming traffic, the speed a request can be dealt with, and the number of requests which we can deal with concurrently, speeding up the application is not realistic, we have no control over the incoming traffic so the last option is scale the number of requests we can deal with per second.
In the previous example, this is opening more checkouts in anticipation.
The Scaling
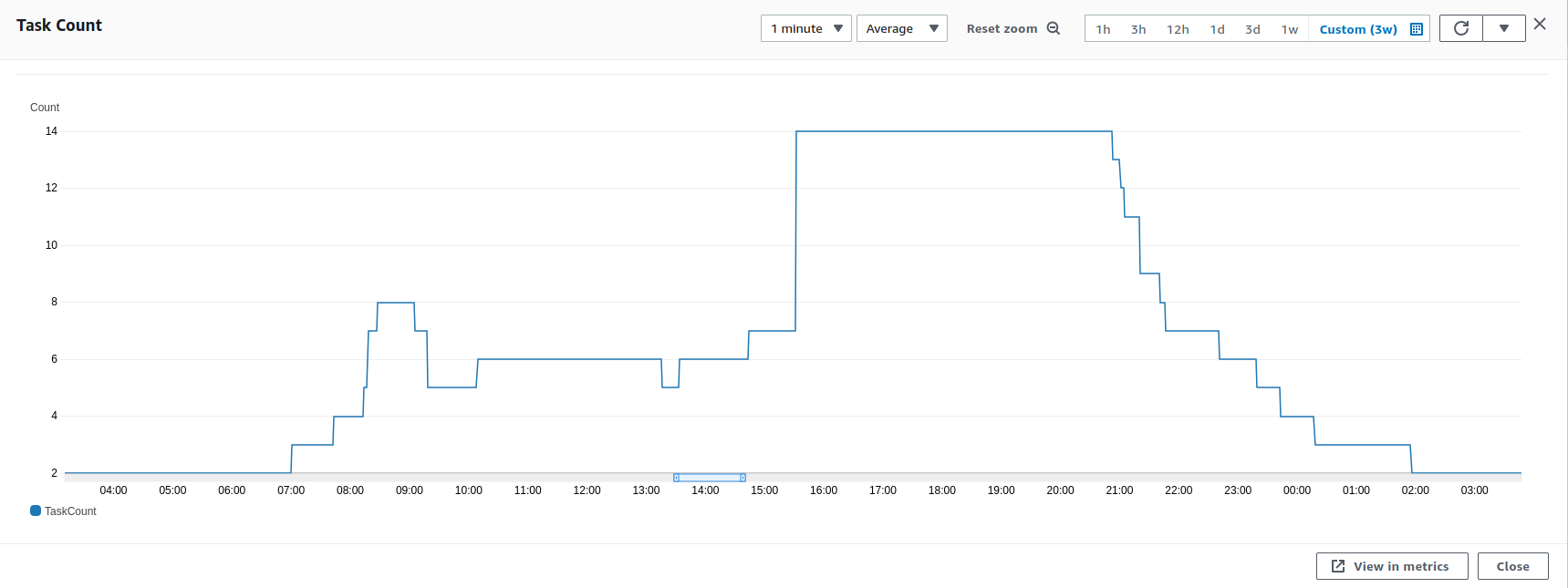
We assumed that the initial scale would be a little bit bigger than our normal peaks, our max container counter in Fargate for the previous month was 13 for the website, so we set the minimum count to be 14, this was much higher than the expected Saturday traffic, but about inline with our busy periods.
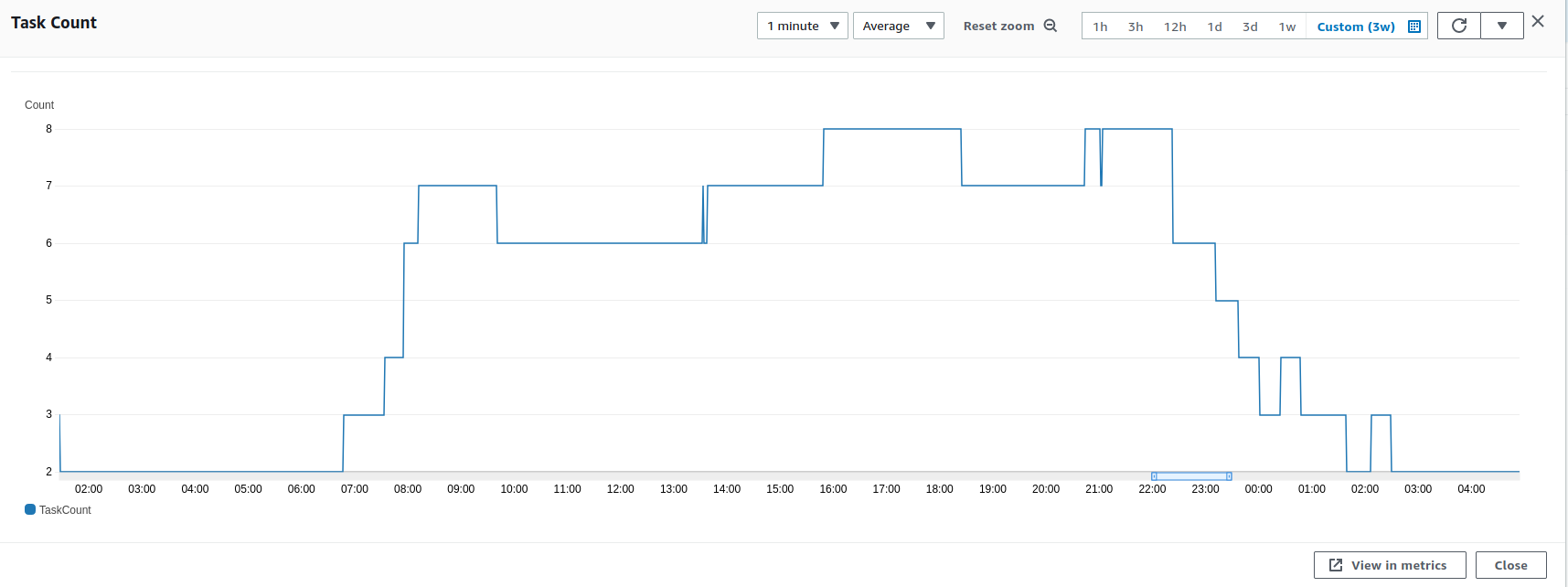
"The Website" at Sykes is a collection of services working together in reality, the above is the main application code scaling, but we still needed to consider the other parts of the website to scale fo example out databases, our caches, our search engine, our other microservices which get specific information about features for example. We scaled all of these services in similar ways, as all of them take advantage of AWS features. We were not sure what pages the users would go to not being the normal profile, so just assumed worst case for all and scaled for that
The Showing
Everything had been prescaled a few hours earlier to make sure everything had settled down and there were no issues.
When the show came on TV a small team of us were watching the show, along with as many monitoring pages as we could see at one time to make sure we could react to what ever was going to come our way. The show was 90 minutes long and the mention could have been at any point.
When the mention did happen we saw traffic jump immediately
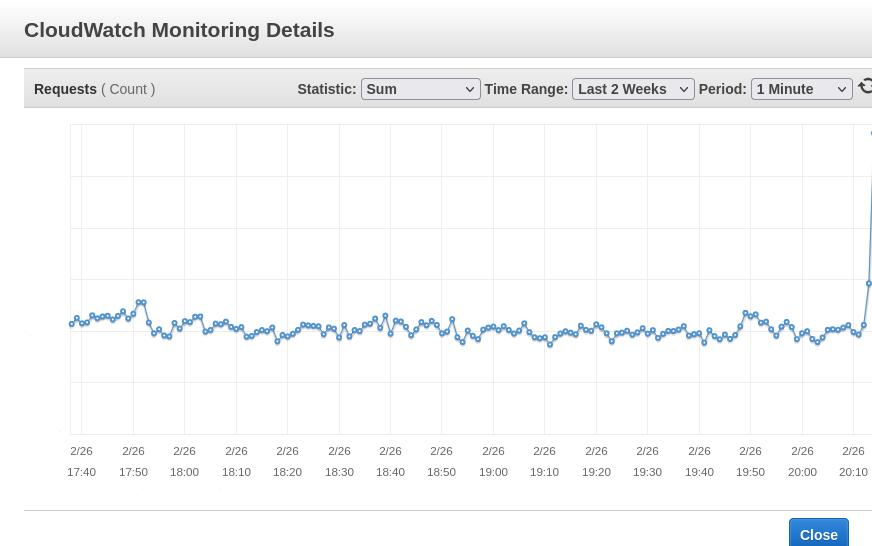
Traffic within 40 seconds was twice the previous traffic!
That is a very large jump! We didn't know where the peak would be, we still had some headroom, but with that sort of growth,
it will run out quickly
 (credit XKCD)
(credit XKCD)
We started looking at scaling up even further, thinking we had underestimated the traffic coming in, as we were doing that the peak seemed to have arrived, at a little over 3x the normal traffic level and was returning back to normal traffic levels quicker than we had thought too.
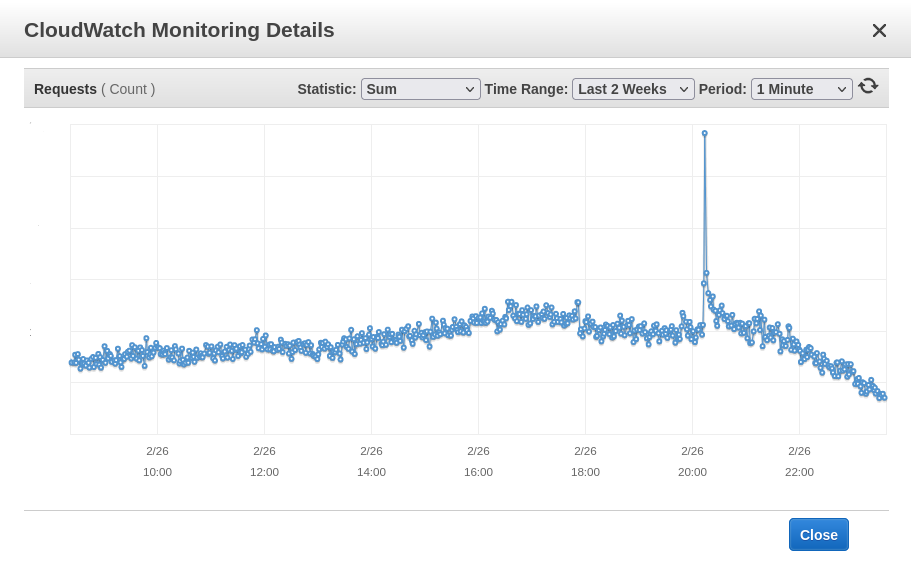
When we were confident that was the peak over we also set the minimum back down to 2 (where it normally is) and let the site scale down itself.
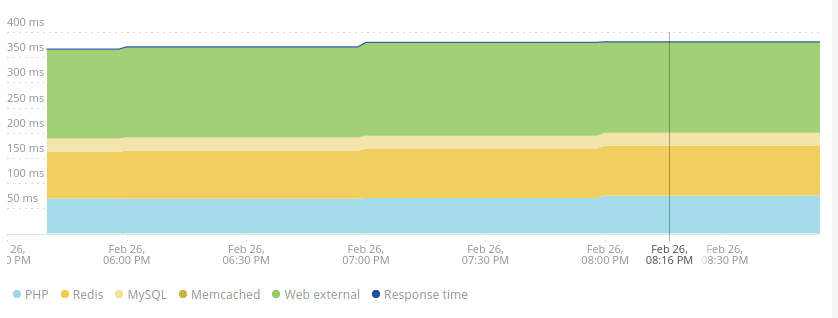
Our Application Monitoring Platform New Relic also shown that we handled the extra traffic just as we would any other traffic, no slow downs and a good experience for customers
Alternatives
Sykes were able to do this easily due to the effort we put into making our application scale, without this ability we would have been left with 3 options:
- Implement a third party "queue" system, these systems only allow a certain amount of people on the website at a single time, and others wait in a queue until they are allowed on
- Use a caching layer such as Cloudfront or Varnish and stop many requests hitting us, as we rely on our applications for A/B testing, we would have lost the ability to run these which was not a good option
- Hope that our service doesn't fall over, which is what a large amount of the early slashdot effect people did.
Summary
Sykes make heavy use of cloud based technologies and our infrastructure is code, doing this allows us to scale easily and quickly to ensure that excess traffic is not the reason we can not serve our customers.
While this sort of traffic is hard to deal with, even taking advantage of cloud technologies, due to the sudden and large rises, we are able to also manually override defaults easily to allow our infrastructure to scale correctly.
If you are interested in making systems like this please check out our current vacancies.