The experience of our customers on the web is a top priority for us and is one of the ways we stay competitive. Our goal is to match customers to their perfect holiday cottage experience and delight at each stage along the way. Getting the data pipeline to fuel this innovation is key and, in this post, we explain more about why and how.
About Data and Analytics at Sykes
The data and techniques shared in this article were produced by the Data and Analytics team at Sykes. If you are a talented Data Scientist, Analyst or Developer please check out our current vacancies.

For several years now Sykes have been innovating and iteratively improving website features through testing, steadily improving our customer satisfaction rates and conversion year on year. As we grow as a business, we are looking for new ways to further innovate our web experience through data.
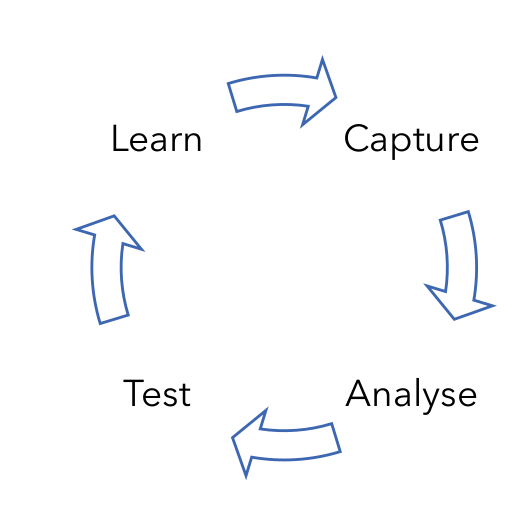
To fuel the next phase of innovation we began by looking at our current data pipeline.
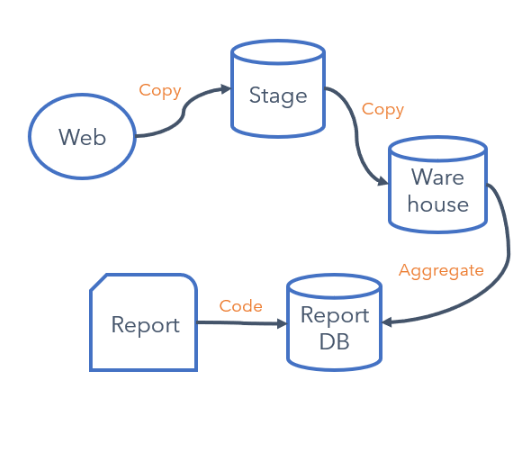
The existing pipeline, whilst serving its purpose for several years, does have problems that impair this cycle.
Very early in this pipeline the data is turned into rows and columns (structured data).
Various copies are made, and the results are presented via a static report. Data engineers are needed for any changes, such as new events or contextual information. Scale is also challenging as this has to be done manually in the main.
Our objective is to simplify this pipeline, make it scalable and self-service.
Conceptually we looked to move to something more like this.
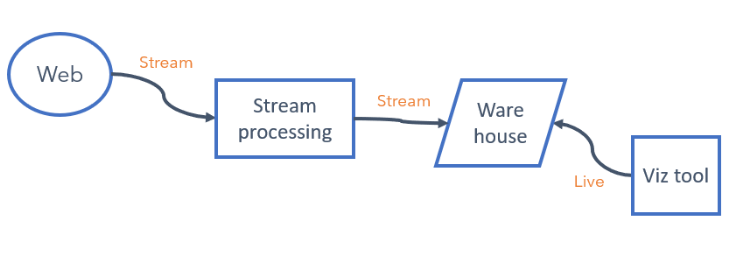
Critically keeping the data in a semi-structured format until it is ingested into the warehouse then using ELT to do a single transformation of the data, we can simplify the pipeline and make it much more agile.
New web events (and any context that goes with it) can we wrapped up within a message and can flow all the way to the warehouse without a single code change. The new events are then available to the web teams either though a query or the viz tool.
Our current throughput is around 50k (peaking at over 300k) messages per minute. As new events are captured this will grow considerably, each of the above components must scale accordingly.
This means the web teams can capture new events, analyse the data using self-service tools with no dependency on Data Engineering.
The business case for doing this is compelling. Based on our testing and projections, we expect at least 10x ROI over 3 years for this investment.
When running our vendor selection process Snowflake for the Data Warehouse was the clear winner. With its powerful scalability features, data ingestion options, familiar SQL language, and DWaaS model, it really stood head and sholders above the other vendors we looked at. Really enabling us as a business to go much faster by massively simplifying this critical pipeline. Coupled with Confluent Kafka we are able to stream data to the warehouse, at scale, in semi-structured formats, and apply any instream processing we need through a simple user interface. A real step change in capability for us.
Over to Simon Prydden now for the technical bit..
How (for the techies)
After a not simple selection process, involving paper-based evaluations, a scoring stage and a hands-on POC or trial usage stage, we decided that our new data pipeline will use Confluent Kafka for data streaming and change data capture and Snowflake Cloud for Data Warehouse Compute and Storage. Those technologies allow us to meet our main requirements that were established at the beginning of this project, around near real time reporting and the flexibility of creating new web events.
Streaming Platform
Using Confluent Cloud for our Kafka needs has allowed us to offload the responsibility of running Kafka, whilst giving us access to a wide range of available ready- made connectors for integrations.
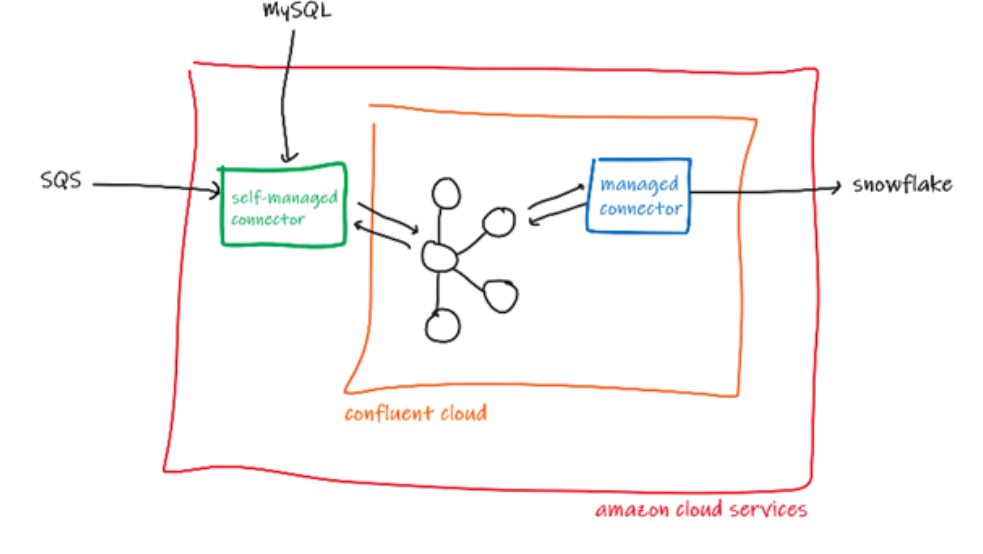
Our setup comprises of a Kafka cluster, two self-managed connectors to import data and one managed connector to export data.
For the self-managed connectors, we extend the Confluent connect base image by installing the required connector files, which are available on the Confluent Hub.
FROM confluentinc/cp-kafka-connect-base:6.0.2
# install the required connector jar file
RUN confluent-hub install --no-prompt debezium/debezium-connector-mysql:1.4.0
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-sqs:1.1.1
Once the connect worker is running, the connector configuration can be loaded into Kafka Connect via the REST API.
PUT /connectors/mysql-source/config HTTP/1.1
Host: connect.example.com
Accept: application/json
{
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"kafka.api.key": "api_key",
"kafka.api.secret": "api_secret",
"database.hostname": "server_name",
"database.port": "server_port",
"database.user": "db_user",
"database.password": "db_password",
"database.server.name": "server_name",
"tasks.max": "1"
}
Once the connector is configured, we can see in the connect worker logs as follows, which indicates the successful ingestion of data from MySQL to Kafka.
[2021-04-21 11:07:42,774] INFO start transaction with consistent snapshot
[2021-04-21 11:07:42,833] INFO read list of available tables in each database
[2021-04-21 11:08:01,564] INFO scanned 48169 rows in 23 tables in 00:00:08.451
We use a managed Snowflake connector to move the data out of Kafka into Snowflake, which can be setup in the Confluent cloud web UI or the command line interface.
cat > snowflake.json
{
"connector.class": "SnowflakeSink",
"topics": "web.events",
"input.data.format": "JSON",
"kafka.api.key": “api_key ",
"kafka.api.secret": "api_secret”,
"snowflake.url.name": "https://xxxxxxx.eu-west-1.snowflakecomputing.com",
"snowflake.user.name": "kafka_connector_user",
"snowflake.private.key": "private_key
"snowflake.database.name": "kafka_db",
"snowflake.schema.name": "kafka_schema",
"name": "snowflake_sink",
"tasks.max": "1"
}
ctrl + d
ccloud connector create --config snowflake.json
Data Warehouse
Using Snowflake for our data warehouse needs has allowed us to scale compute and storage independently, whilst providing native support for semi-structured data.Every Snowflake table loaded by Kafka connector consists of two variant columns, a metadata and content column, which can be queried using SQL select statements and JSON dot notation.

We utilise Snowflake tasks and streams on the table created by the connector to process newly inserted rows and flatten the message within the content column into a reporting table.
CREATE STREAM kafka_topic_stream ON TABLE “kafka_db”.”kafka_schema”.”kafka_topic”;
CREATE TASK flatten_kafka_topic
WAREHOUSE = xs_warehouse
SCHEDULE = '1 minute'
WHEN
SYSTEM$STREAM_HAS_DATA('kafka_topic_stream')
AS
INSERT INTO fct_web_events
SELECT
rv.RECORD_CONTENT:user_id::string(50) AS user_id,
rv.RECORD_CONTENT:event_timestamp::TIMESTAMP_TZ(0) AS event_timestamp,
rv.RECORD_CONTENT:session_id::string(50) AS session_id,
rv.RECORD_CONTENT:event_type::string(50) AS event_type,
rv.RECORD_CONTENT:user.device_type::string(50) AS device_type,
rv.RECORD_CONTENT:user.platform::string(50) AS platform,
exp.key::string(50) AS variation,
var.value::int AS experiment_instance_id
FROM kafka_topic_stream AS rv
, LATERAL FLATTEN( INPUT => rv.RECORD_CONTENT:experiment ) AS exp
, LATERAL FLATTEN( INPUT => exp.value ) AS var
WHERE METADATA$ACTION = 'INSERT';
Now the data is available to be self-served by the web teams, in near real-time, using the preferred data viz tool. In our case, the experimentation dashboard has been created using a live Tableau connection.